[Spring]추천 알고리즘 - 콘텐츠 기반 필터링
내가 진행한 프로젝트는 사용자에게 크게 2가지 측면의 서비스를 제공한다.
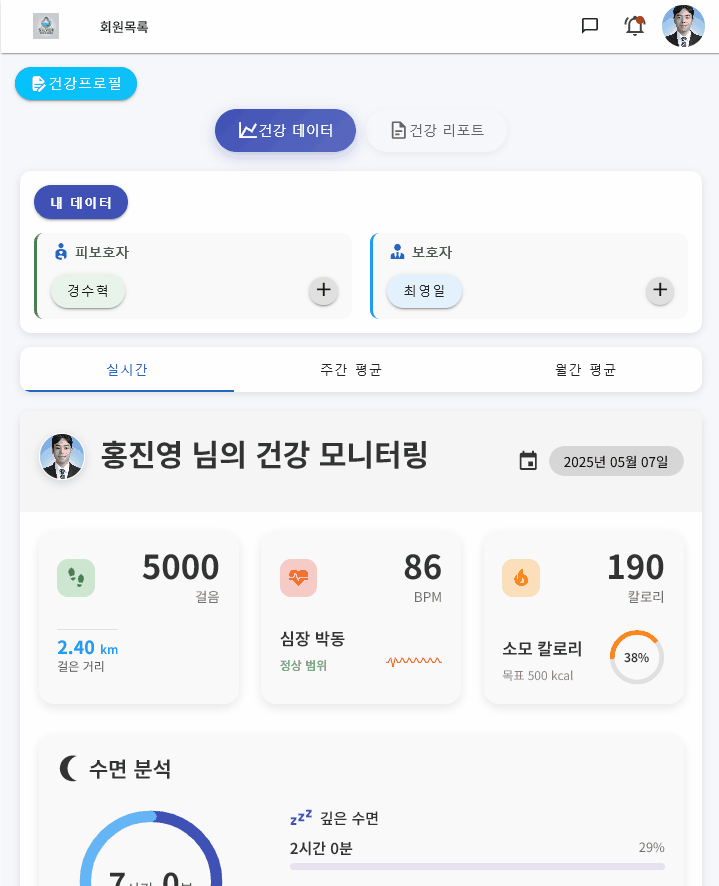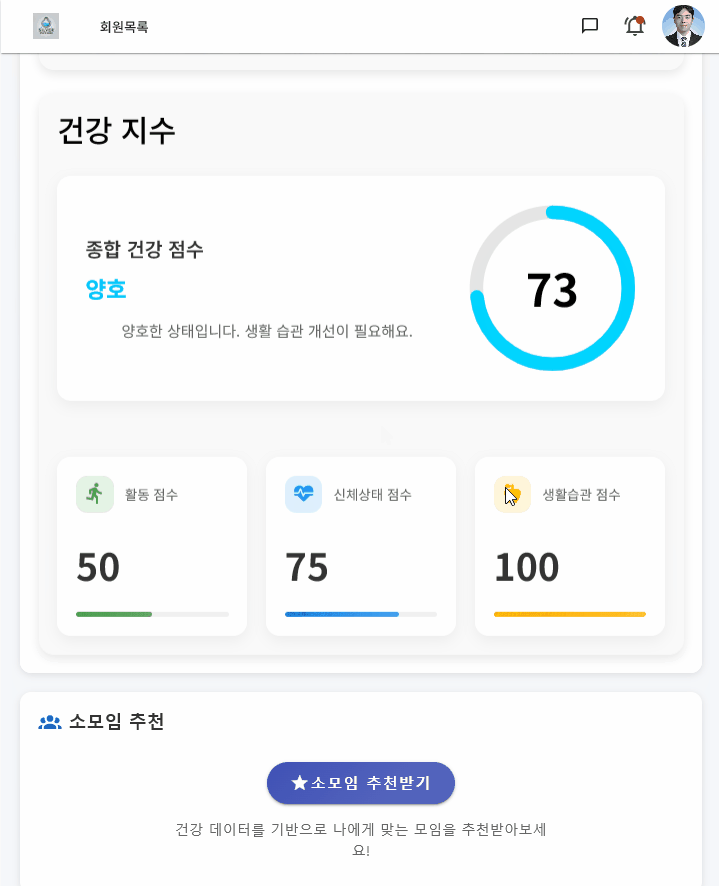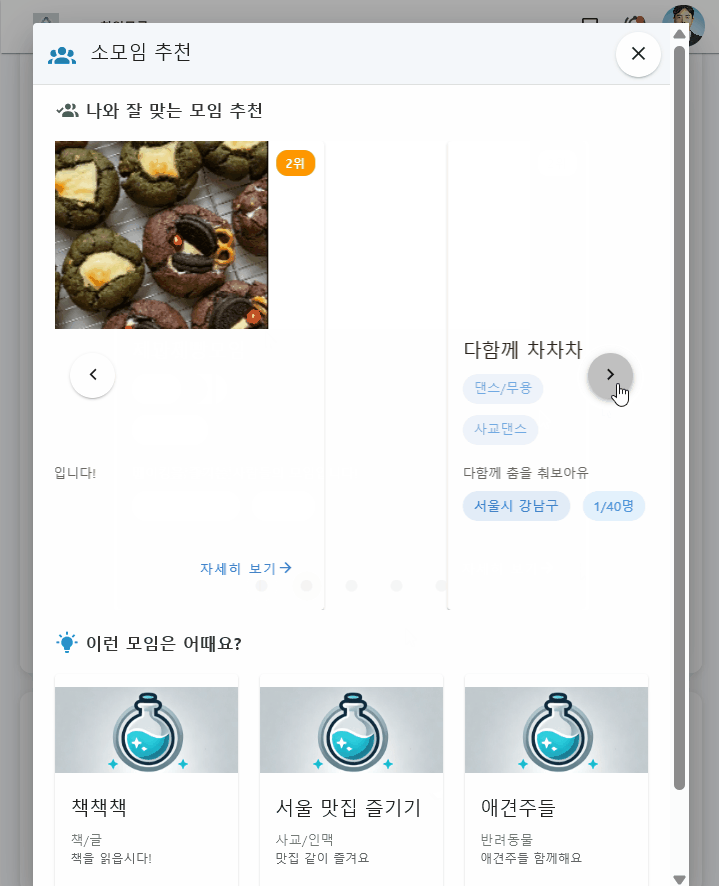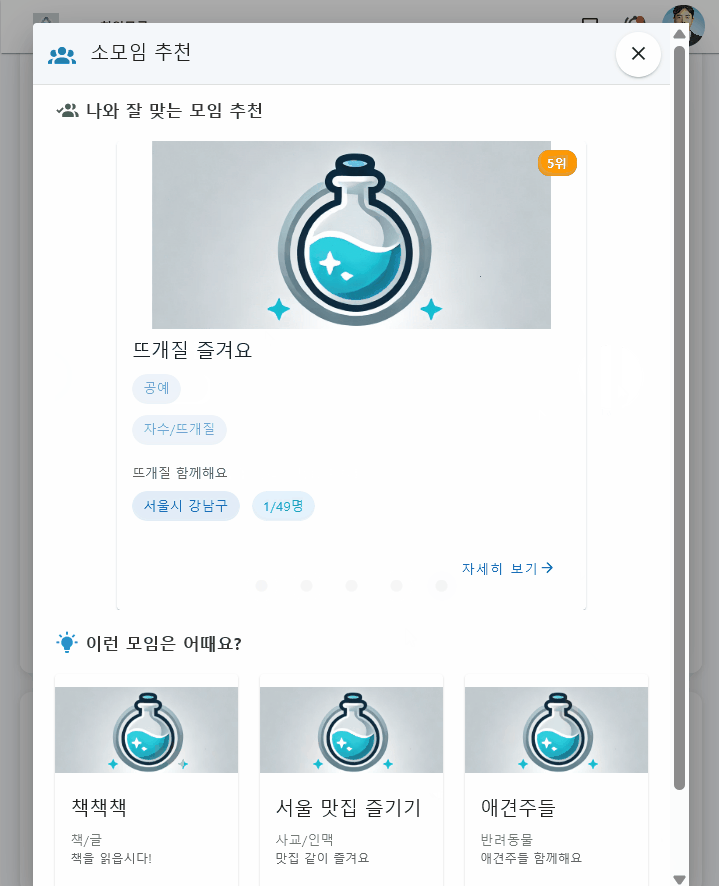
하나는 스마트 워치로 부터 연동된 건강데이터(걸음수, 심박수, 수면 등) 모니터링 서비스를 제공하는 것이고
다른 하나는 사용자에게 운동,독서,취미,요리 등 다양한 소모임 공간을 제공하는 것이다.
우리의 서비스는 실버세대를 타깃으로 하여 건강 모니터링 서비스를 통해 실버세대들의 신체적 건강을 증진시키고,
소모임 커뮤니티 공간을 제공하여 실버세대들의 사회적 고립감을 해소하여 정서적 건강을 향상시키는 것이 목적이었다.
그러나, 실버세대들의 신체적 건강과 정서적 건강 측면 두 가지를 향상시킨다는 목적이 있음에도 불구하고
건강모니터링 서비스와 소모임 서비스의 '분절성'이 도드라졌다.
그래서 도입한 것이 개인의 건강과 성향을 바탕으로 적합한 소모임을 추천하는 것이었다.
그렇다면 추천 알고리즘을 구현하는 방식은?
추천 알고리즘을 구현하는 방식에는 대표적으로 두 가지 방식이 있다.
1. 콘텐츠 기반 필터링
2. 협업 기반 필터
콘텐츠 기반 필터링은 유저와 콘텐츠에는 어떠한 특성을 나타내는 값들이 있고, 그 값들이 유사하면 유저에게 그 콘텐츠를 추천하는 것이다.
예를 들어, 드라마에 다양한 특성을 잡는다 치면,
이 드라마에 액션이 어느정도인지, 로맨스는 어느정도인지, 한국드라마인지, 어떤 배우가 나오는지, 어떤 감독이 나오는지 등 정말 다양한 특성을 잡을 수 있다.
그리고 나라는 사람은 액션은 0.8(1이 100점 만점이라고 생각하면 된다), 로맨스는 0, 한국 드라마, 이성민 배우에 대한 선호도가 높다는 값이 세팅되어있다면 나에게 그러한 특성값을 가지고 있는 드라마가 추천될 것이다.
또 다른 예시는 쇼핑몰에서 내가 방금 본 제품과 유사한 제품보기 라는 탭에서 주로 구현되어있다.
내가 방금 본 제품에 대한 특성값과 비슷한 값을 가진 제품군들이 나에게 추천되는 것이다.
협업 기반 필터링은
나와 취향이 비슷한 사람들이 선호하는걸 나에게 추천해주는 것이다.
예를 들어, 나는 폭삭 속았수다, 쌈마이웨이 작품에 대해 높은 평점을 남겼다면 마찬가지로 폭삭 속았수다,쌈마이웨이 작품에 높은 평점을 남긴 사람들이 또한 동백꽃 필 무렵에 대해 높은 평점을 남긴 것을 보고 나에게 동백꽃 필 무렵을 추천해주는 것이다.
콘텐츠 기반 필터링을 선택한 이유는?
나는 이 중 유저에게 적합한 소모임을 추천하는 알고리즘에 콘텐츠 기반 필터링을 적용하여 개발하기로 결정했다.
그 이유는 데이터가 적어도 콘텐츠 기반 필터링은 나의 선호도와 콘텐츠의 선호도만 비교하므로 추천의 퀄리티가 유의미하기 때문이다. 만약, 유저들이 엄청 많은 서비스라고 한다면 협업 기반 필터링의 추천 퀄리티가 높을 것이다.
먼저 , 알아야 할 개념이 있다.
벡터
벡터는 여러 개의 숫자를 나열한 리스트다. 즉 수치화 된 특성을 한 줄로 표현한 것이다.
이 벡터가 있어야 컴퓨터는 유저간 혹은 컨텐츠간 혹은 유저와 콘텐츠간의 유사성을 수학적으로 계산 할 수 있다.
예를 들어, 액션/ 로맨스/ 공포/ 스릴 이 4가지 특성으로 콘텐츠를 표현한다면 [0.8, 0.2, 0.5, 0.6] 이렇게 표현 된 것이 벡터다.
액션,오맨스,공포,스릴 4가지 차원에 대해서 4개의 숫자로 이루어진 4차원 벡터값이라고 표현한다.
(차원이 높을 수록 추천의 품질이 높아질 것이다...)
그리고 벡터값 안의 하나하나의 값들 0.8 / 0.2 .. 이런 것들은 스칼라라고 표현한다.
그리고 유저에 대해서는 액션에 선호도/로맨스에 대한 선호도/공포에 대한 선호도/스릴에 대한 선호도 이 4가지 특성으로 표현한 [0.7,0.1,0.4,0.6] 벡터값을 가지고 있다면 유저의 벡터와 콘텐츠에 대한 벡터를 비교해서 2개가 비슷하다? 그러면 그 유저에게 이 콘텐츠를 추천하는 것. 이것이 콘텐츠기반 필터링이다.
그리고 이렇게 벡터간 비교를 위해서는 차원이 같아야하고 같은 특성에 대한 값이어야한다.
유사도 로직
유사하다는 것은 수학적으로 생각했을 때, 거리가 가깝다고 생각하면 된다.
예를 들어 어떤 콘텐츠의 한가지 특성값은 0으로 갈 수록 사회적 뉴스, 1로 갈 수록 경제적 뉴스이고(Y좌표). 다른 한 가지 특성값은
0으로 갈수록 진보적 성향을 띄고 1로 갈수록 보수적 성향을 지닌다고 해보자(X좌표) ==> 즉 2차원 벡터값이다.
유저도 같은 벡터를 가지고 있고,
유저의 벡터 좌표와 컨텐츠의 벡터 좌표 두 지점 사이의 직접적인 거리가 가까울 수록 유사하다고 판단할 수도 있고,
서로 지향하는 방향이 비슷할 수록 유사하다고 판단할 수도 있다.
이 때, 두 지점 사이의 거리를 계산하는 것이 유클리드 거리 계산법
두 지점이 이루는 각도를 계산하는 것이 코사인 유사도 방식이다.

1.벡터값 저장
먼저 나는 유저 벡터 엔티티와 소모임 벡터 엔티티를 만들고 각각 유저-유저벡터 / 소모임-소모임벡터 1:1 관계를 맺었다.
유저 벡터는 유저로부터 설문조사로 정서적 지원 필요성/성취성/사교성/활동성 이 4가지 차원의 값을 계산해 저장시켰다.
이때 저장 되는 값들은 모두 0과 1사이로 정규화 된 값이어야한다.
@AllArgsConstructor
@NoArgsConstructor
@Getter
@Entity
public class UserVector {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
//정서적 지원 필요성 (설문조사 9점 + 수면데이터 6점으로 3:2비율)
private double empathyNeeds;
//성취성 (설문조사 6점)
private double achievement;
//사교성 (설문조사 6점)
private double connectivity;
//활동성 (설문조사 9점 + 활동점수(걸음,칼로리,운동습관) 9점으로 1:1 비율)
private double energy;
//유저
@OneToOne
@JoinColumn(name = "user_id")
private User user;
// //절대값
// @OneToOne(mappedBy = "user_vector", cascade = CascadeType.ALL, orphanRemoval = true, fetch = FetchType.LAZY)
// private UserVectorBefore userVectorBefore;
}마찬가지로 소모임 벡터도 각각의 기준에 따라 점수를 매겨 저장시켰다.
@AllArgsConstructor
@NoArgsConstructor
@Getter
@Entity
@Builder
public class GatheringVector extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
//정서적 지원 필요성(30점만점)
private double empathySupport;
//성취성(30점만점)
private double achievementSupport;
//사교성(20점 만점 이나 향후 모임,정모수에 따라 추가)
private double connectivitySupport;
//활동성(20점만점)
private double energySupport;
@OneToOne
@JoinColumn(name = "gathering_id")
private Gathering gathering;
public GatheringVectorForUserServiceDto toDtoForUserService(){
return GatheringVectorForUserServiceDto.builder()
.id(this.gathering.getId())
.empathySupport(this.empathySupport)
.achievementSupport(this.achievementSupport)
.connectivitySupport(this.connectivitySupport)
.energySupport(this.energySupport)
.build();
}
}
이 소모임이 얼마나 사교적인 모임인지, 활동적인 모임인지, 성취적인 모임인지 등 판단하는 기준은 내가 아래의 기준에 따라 자의적으로 만들고 점수화하였다.
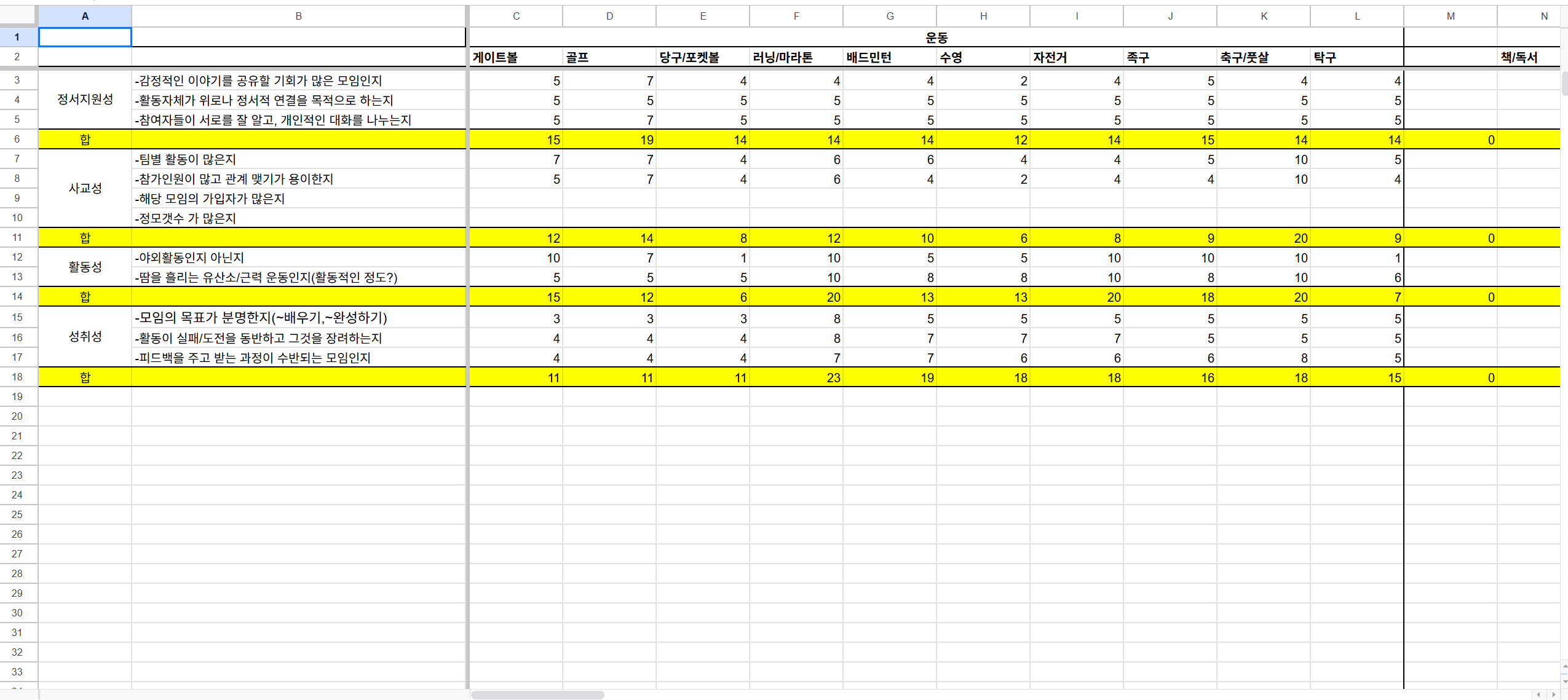
// 스코어는 현재점수, 맥스는 그 항목의 최대 점수
// 정규화하는 함수
public static double normalize(double score, int max){
if(max<=0.0) return 0.0;
return Math.min(Math.max(score / (double)max, 0.0),1.0);
}
2.코사인 유사도
아래 클래스는 내가 유저벡터를 만드는데 필요한 계산들을 쉽게 하기 위해 따로 만든 유틸리티 클래스이다.
여기서 볼 점은 코사인 유사도 메서드 부분만 보면 될 것이다.
//추천에 필요한 유틸리티 클래스
public class UserVectorUtils {
// 스코어는 현재점수, 맥스는 그 항목의 최대 점수
// 정규화하는 함수
public static double normalize(int score, int max){
if(max<=0) return 0.0;
return Math.min(Math.max(score / (double)max, 0.0),1.0);
}
public static int sleepToEmpathyNeeds(HealthData healthData){
int sleepMinutes = healthData.getTotalSleepMinutes();
// 11시간 이상(660분 이상) 또는 5시간 미만(300분 미만) → 매우 부적절
if (sleepMinutes >= 660 || sleepMinutes < 300) {
return 6;
}
// 10시간 이상(600분 이상) 또는 6시간 미만(360분 미만) → 부적절
else if (sleepMinutes >= 600 || sleepMinutes < 360) {
return 4;
}
// 6시간 ~ 7시간(360~420분) → 약간 부족
else if (sleepMinutes >= 360 && sleepMinutes < 420) {
return 2;
}
// 7시간~9시간(420~540분) → 적절
else {
return 0;
}
}
//활동점수를 에너지벡터에 더하기 위해 활동점수를 0~9점으로 변환하는 메서드
public static double activityScoreToEnergyScore(HealthScore healthScore){
int activityScore = healthScore.getActivityScore();
return (activityScore /100.0) * 9.0;
}
//유저의 정규화된 벡터값 만들어주는 함수
public static double[] makingUserVector(User user){
//정서적 지원 필요성 (설문조사 9점 + 수면데이터 6점으로 3:2비율)
int empathyNeeds =0;
//성취성(설문조사 6점)
int achieveScore =0;
//사교성(설문조사 6점)
int connectivityScore =0;
//활동성(설문조사 9점 + 활동점수(걸음,칼로리,운동습관) 9점으로 1:1 비율)
double energyScore =0;
//벡터 값 계산에 필요한 사용자의 설문조사 객체
UserDetailHealthInfo usersHealthInfo = user.getUserDetailHealthInfo();
//벡터 값 계산에 필요한 사용자의 헬스데이터인데 월별이 있다면 월별데이터를 가지고 오고 없다면 주간 없다면 일간을 가져옴
List<HealthData> healthDataList = user.getMyHealthData();
HealthData selectedHealthdata = healthDataList.stream()
.sorted(
Comparator
.comparingInt((HealthData d) -> d.getDataType().getPriority()) // 타입 우선순위 낮은 게 먼저(즉 월별,주간,일간)
.thenComparing(HealthData::getCreatedDate, Comparator.reverseOrder()) // 그러고나서 생성날짜가 제일 최신으로
)
.findFirst().orElseThrow(()->new EntityNotFoundException("일간 헬스 데이터도 없습니다"));
//벡터 값 계산에 필요한 사용자의 헬스스코어인데 마찬 가지로 월별이 있다면 월별데이터를 가지고 오고 없다면 주간 없다면 일간을 가져옴
List<HealthScore> healthScores = user.getHealthScores();
HealthScore selectedHealthScore = healthScores.stream()
.sorted(
Comparator
.comparingInt((HealthScore d) -> d.getType().getPriority()) // 타입 우선순위 낮은 게 먼저(즉 월별,주간,일간)
.thenComparing(HealthScore::getCreatedDate, Comparator.reverseOrder()) // 그러고나서 생성날짜가 제일 최신으로
)
.findFirst().orElseThrow(()->new EntityNotFoundException("일간 헬스 점수도 없습니다"));
//정서적 지원 필요성에 필요한 데이터들
int serveyScoreForEmpathy = usersHealthInfo.getEmpathyNeedScore();
int sleepDataScore = sleepToEmpathyNeeds(selectedHealthdata);
empathyNeeds = serveyScoreForEmpathy + sleepDataScore;
//성취성
achieveScore = usersHealthInfo.getAchieveScore();
//사교성
connectivityScore = usersHealthInfo.getPeopleConnectivityScore();
//활동성
int serveyScoreForActivity = usersHealthInfo.getEnergyScore();
double activeHealthDataScore = activityScoreToEnergyScore(selectedHealthScore);
energyScore = serveyScoreForActivity + activeHealthDataScore;
return new double[]{
normalize(empathyNeeds,15),normalize(achieveScore,6),normalize(connectivityScore,6),normalize((int)energyScore,18)
};
}
//코사인 유사도
//2개의 인자 2개의 벡터값
public static double cosineSimilarity(double[]a, double[]b){
double dot =0.0; //내적(Dot Product). 내적이란, 같은 차원의 벡터가 있을때 대응하는 요소끼리 곱해서 전부 더한 것으로 내적이 클수록 두 벡터는 비슷한 방향. 내적이 0이면 수직. 내적은 코사인 유사도의 분자 부분
double normA =0.0; //여기서 norm은 벡터의 크기
double normB =0.0; //벡터 b의 길이
for(int i = 0; i< a.length; i++){
dot += a[i]* b[i];
normA += a[i] *a[i];
normB += b[i] * b[i];
}
if(normA ==0 || normB ==0)return 0.0;
return dot/(Math.sqrt(normA) * Math.sqrt(normB));
}
//유클리드 거리 계산
public static double euclideanDistance(double[]a, double[]b){
if(a.length != b.length) throw new IllegalArgumentException("벡터간 길이 불일치");
double sum = 0.0;
for(int i=0; i<a.length; i++){
sum +=Math.pow(a[i]-b[i],2); //벡터의 각 차이의 제곱을 sum에 더함
}
return Math.sqrt(sum);
}
3.두 벡터간 코사인 유사도 계산
아래 로직이 한 유저가 소모임 추천받기를 눌렀을 때 작동되는 로직이다.
그 유저의 벡터값을 가지고 오고 모든 소모임들의 벡터값을 가지고 와 코사인 유사도 로직을 이용하여 유사한 상위 5개 모임을 뽑아내는 것이다.
아래 코드는 내 서비스에 맞게 작성한 것이라 처음 보면 이해하기가 어려울 것이다.
따라서 유저인 나와 콘텐츠의 벡터간의 유사도를 계산하여 유사도가 가장 높은 순으로 상위 몇개를 필터링한다는 것만 생각하여 로직을 구성하면 될 것이다.
// 1.사용자에게 맞는 소모임 5개 추천 성향과 다른 소모임 3개추천
public Map<String,List<GatheringInfoDtoForUserServiceDto>> recommendGatherings(String loginId){
User user = userRepository.findByLoginIdAndDelYN(loginId, DelYN.N).orElseThrow(()->new EntityNotFoundException("없는 회원입니다"));
//유저 벡터값 계산
double[] userVector = UserVectorUtils.makingUserVector(user);
List<GatheringVectorForUserServiceDto> allGatheringVectors = postClient.allGatheringsForUserService();
//코사인 유사도가 가장 유사한 모임 아이디 5개 뽑아내기, //AbstractMap.SimpleEntry는 자바에서 키-값 쌍을 만드는 간단한 묶음 (여기서는 게더링 아이디와, 유사도를 묶었음)
List<Long> top5Ids = allGatheringVectors.stream().map(gv->new AbstractMap.SimpleEntry<>(
gv.getId(), UserVectorUtils.cosineSimilarity(userVector,gv.toVectorValue())
))//아래에서 부터 유사도 점수를 기준으로 내림차순 정렬.그러면 유사도가 높은 소모임이 앞으로 옴.그럼다음 앞에서 5개 끊고.Map.Entry객체에서 키(여기서는 아이디만) 가지고 온다
.sorted((a,b) -> Double.compare(b.getValue(),a.getValue())).limit(5).map(Map.Entry::getKey)
.toList();
List<GatheringInfoDtoForUserServiceDto> similarGatherings = postClient.fiveRecommendedGatherings(top5Ids);
구성된 화면은 아래와 같다.
실제로 나의 성향을 사교성과, 활동성, 성취성을 매우 낮게 세팅하면 독서모임과 같은 정적인 모임들이 추천되었고,
높게 세팅한 뒤 추천을 돌리면 운동, 사교 모임 같은 것들이 추천되었다.
조금 더 추천의 퀄리티를 높이고자한다면 벡터 차원을 훨씬 높여야 할 것 같다.